Visual Studio の診断をインラインで表示する機能が便利 | v17.1.0 以降
今まで知らなかったのですが、「診断をインラインで表示(Display diagnostics inline)」する機能が便利です。
通常、コンパイルエラーや警告は該当箇所をマウスオーバーしないと見れなかったのですが、この機能を有効にするとマウスオーバーなしで常にエディタ上に表示されます。
- これまで

- 診断をインラインで表示を有効にする

この機能は Visual Studio の v17.1.0 以降で使用できるようです。機能を有効にするには[ツール] - [オプション] - [テキスト エディター] - [C#] - [詳細]にある診断をインラインで表示(試験的)のチェックを ON にしてください。コードの末尾でとエディター ウィンドウの右端が選べますが、表示位置が変わるだけです。また、VB.NET でも同じ設定が使えます。

コンパイルエラーになるコードを書いたときにもリアルタイムに表示されます(これはちょっと邪魔かも…)。

コード書くことに集中すると警告のことを忘れがちなんですが、この機能によって可視化されることで修正漏れを減らすことができそうです。
C# と Google Fitness API を使って体重の取得と登録を行う
今年、健康診断で再検査して、LDL コレステロール値と尿酸値が上がってしまう悲惨な結果を受けました😭仕方ないので、数値の改善を目的としてフィットネスバイクとスマートバンドを購入し、日々の体重記録を行うことにしました。せっかくなので Google Fit を使って継続的にデータを記録したいな~と思い、過去に記録した体重データも登録する手段を探しました。
ここでは、Google Fitness API + C# を使用して Google Fit に体重データを記録するまでの流れをまとめています。
- 概要
- Google Fitness API を使うための事前準備
- Google Fitness API を使って体重データを取得する
- Google Fitness API を使って体重データを登録する
概要
Google Fit を使って過去に別の手段で記録した体重データを登録します。私の場合、体重データを Google Spread Sheet で記録していたので、それを CSV ファイルで出力して Google Fit に記録したいと考えました。
Google Fit を選んだ理由は「使用しているスマホが Android である」ことと「購入したスマートバンドの連携先に Google Fit があった」ことです。スマホは Pixel6 Pro を使用して、スマートバンドは Xiaomi の Smart Band 8 です。スマートバンドは体重データを記録するものではないのですが、毎日体重を記録するならサービスは統一したほうがいいかなと思い Google Fit を使うことにしました。
 Smart Band 8 スマートウォッチ 進化したディスプレイ 16日間持続バッテリー クイックリリース構造 150種類スポーツモード 24時間健康管理 スマートバンド 着信通知・LINEアプリ通知 iPhone&Android対応 グラファイトブラック")
やりたいこと
前述した通り、過去に記録した CSV 形式の体重データがあるので、それを Google Fit に登録します。体重データは次のように日付、体重の2つの情報が記録されています。
| 日付 | 体重 |
|---|---|
| 2023/08/16 | 67.75 |
| 2023/08/17 | 68.3 |
| 2023/08/19 | 67.75 |
先に結果だけお見せしておきます。このように Google Fit を確認すると、過去の体重データが記録されるようになります。


開発環境
このエントリでは次の開発環境、及び言語、ライブラリを使用するものとします。
- 開発環境: Visual Studio 2022 Comunity Edition
- 言語: C# / .NET8
- ライブラリ:
Google Fit に体重データを登録するための前提知識
まず、Google Fitl に登録するためには、次の情報について理解しておく必要があります。ざっくり説明すると、Google Fit アプリに体重データを記録するには、Google Cloud API に含まれる Google Fitness API を使用する必要があります。今回は、C# / .NET でこの Google Fitness API を使用します。
Google Fit について。これは Android もしくは iPhone のアプリとして提供されていて、PC から操作・閲覧することはできません。
www.android.com
Google Cloud API について。Google が提供しているサービスの各種 Web API です。
cloud.google.com
Google Fitness API について。Google Cloud API にある、Google Fit のデータにアクセスするための Web API です。今回はこちらを使用して体重データの取得と登録を行います。
developers.google.com
Google Fitness API を使うには?
Google Cloud API の中にある Google Fitness API を使うためには、Google Cloud API クライアントライブラリが必要です。Google Cloud API は、複数言語向けに提供されています。
developers.google.com
.NET 向けにも NuGet Gallery | Google.Apis.Fitness.v1 1.68.0.3232 が提供されています。こちらは記事作成の2024年4月時点で .NET8 に対応しています。
Google Cloud API の認証・認可について
Google Cloud API を使用するためには認証・認可について知っておく必要があります。基本的には以下のページを読んでおけばよいです。 cloud.google.com cloud.google.com
今回は Google Cloud API の OAuth2.0 を使用します。というか、Google Fitness API は個人情報を扱うため、OAuth2.0 しか使えません。.NET で使用する場合は以下のページを読んでおけば問題ありません。
developers.google.com
Google Fitness API を使うための事前準備
Google Finess API を使うためにはいくつかの事前準備が必要です。ここでは、Google Fitness API を使用するために必要な手順について説明します。
- プロジェクトを作成する
- API を有効化する
- OAuth 同意画面を設定する
- 認証情報を追加する
プロジェクトを作成する
ここで言うプロジェクトとは、Google Cloud API の権限を管理したり API の使用者や共同管理者の追加と削除などを行う単位を表します。Google Cloud API では、プロジェクト単位で特定の API を有効化できます。
プロジェクトの作成手順は次のページを参照してください。
cloud.google.com
API を有効化する
Google Fitness API を有効化するには Google Cloud コンソールからFitness APIを探して[有効にする]をクリックします。 有効化できたら API とサービスの詳細画面が表示されます。
console.cloud.google.com

OAuth 同意画面を設定する
同意画面というのは Google Cloud API を使用する際、ユーザーに情報を参照することを通知して同意するかどうかを選択する画面のことです。今回のケースでは、同意するのは自分自身なので、他人が使用することは考慮しないものとします。[認証情報]メニューの[+ 認証情報を作成]から、[OAuth クライアント ID]を選択します。同意画面の設定が必要になるので、[同意画面を設定]を選択します。

以降はアプリの情報を登録することになります。登録する情報は次の通りです。前述した通り、同意画面を表示するのは自分だけなので最低限の情報のみ設定します。設定できたら[保存して次へ]を選択します。
User Type: 外部アプリ名: 任意の名称(同意画面に表示されます)ユーザー サポートメール: 自分のアカウント
Google Cloud API では、使用する API によっては権限が必要です。Google Fitness API は個人情報へアクセスするため、「制限付きのスコープ」に該当する権限が必要です。以下の[スコープを追加または削除]を選択します。

フィルタでFitness APIと入力して、以下のスコープを選択します。選択できれば[更新]を選択します。
https://www.googleapis.com/auth/fitness.body.readhttps://www.googleapis.com/auth/fitness.body.write
スコープが設定できたら[保存して次へ]を選択します。

テストユーザーは、データの取得と登録さえできればよいので自分のアカウントを設定します。設定できれば[保存して次へ]を選択します。これで同意画面の設定は完了です。
認証情報を追加する
OAuth2.0 の認証を追加します。[認証情報]メニューの[+ 認証情報を作成]から、[OAuth クライアント ID]を選択します。今回はコンソールアプリを使うため、デスクトップ アプリを選択します。名前は管理画面でしか出てこないので、任意の値を設定してください。[作成]を選択すると OAuth クライアントが作成されます。

以下のようなダイアログが出てくるので[JSON をダウンロード]で認証情報をダウンロードします。このファイルは後で実装する際に使用します。

これで実装に必要な Google Cloud API の準備が整いました。
Google Fitness API を使って体重データを取得する
体重データを登録する前に、まずは Google Fitness API を使ってどういったデータ構造になっているのかを確認します。
実装
先に実装した結果だけ記載します。
これを実行すると次のような結果が得られます。事前に体重データを登録しています。
======== Start ======== 2024-04-20 - 61.80kg 2024-04-22 - 62.20kg 2024-04-23 - 61.70kg 2024-04-24 - 61.60kg 2024-04-25 - 61.00kg 2024-04-26 - 61.40kg 2024-04-27 - 61.50kg 2024-04-28 - 62.10kg ======== Finish ========
解説
実装内容について解説します。まずは OAuth 認証部分です。この実装サンプルは以下ページにも記載されています。
developers.google.com
Google Cloud API の .NET 向けライブラリでは、GoogleWebAuthorizationBroker.AuthorizeAsyncで認証を行います。第1引数には事前準備しておいた JSON ファイルを使用します。第2引数には、使用する API のスコープを設定します。第3引数はuser固定です。この認証情報をFitnessServiceに渡すことでクライアントが利用可能になります。
var credential = await GoogleWebAuthorizationBroker.AuthorizeAsync( GoogleClientSecrets.FromFile("GoogleAPI.Authorize.json").Secrets , [ FitnessService.Scope.FitnessBodyRead ] , "user" , CancellationToken.None); var fitnessクライアント = new FitnessService(new BaseClientService.Initializer { HttpClientInitializer = credential, });
このクライアントを生成すると、ブラウザが起動して同意画面が表示されます。個人情報へのアクセスに同意が求められるのでチェックを付けて同意してください。同意しないと Google Fit に登録したデータを取得する権限が付与されません。
次に体重データを取得するための条件を指定します。
var 体重データリスト = fitnessクライアント.Users .Dataset .Aggregate(body: new AggregateRequest { StartTimeMillis = DateTime.Today.AddDays(-10).ToGoogleTime() , EndTimeMillis = DateTime.Today.ToGoogleTime() , AggregateBy = new List<AggregateBy> { new AggregateBy { DataTypeName = "com.google.step_count.delta" , DataSourceId = "derived:com.google.weight:com.google.android.gms:merge_weight" } } } , userId: "me") .Execute() .Bucket .SelectMany(x => x.Dataset[0].Point) .ToArray();
使用しているのは以下の API です。条件の指定に必要なプロパティの解説も記載されているので、一度確認しておいてください。
developers.google.com
上記のコードは、特定のデータソースで登録した体重データを集約しています。データソースは、データを登録したデバイスやアプリケーションのことで、Google Cloud API ではDataSourceIdによって一意に識別します。上記のコードではderived:com.google.weight:com.google.android.gms:merge_weight(これは Android のスマホから入力)のデータソースから体重データを取得しています。
データタイプDataTypeNameは、Google Fit で扱うデータの型名です。アクティビティや身体データなど、ある瞬間や一定期間内に集約したデータであることを示します。com.google.step_count.deltaは、1日単位の体重データの合計を集計することができます。
集計期間には次のプロパティを使用します。いずれもミリ秒単位なので、拡張メソッド.ToGoogleTime()を使ってDateTime型からlong型へ変換しています。
StartTimeMillis: 収集開始日時EndTimeMillis: 収集終了日時
あとは集約したデータを順番に出力しているだけです。Google Cloud API のレスポンスの日時はミリ秒、もしくはナノ秒のlong型です。これらもDateTime型に変換できるように.FromGoogleTime()という拡張メソッドを作って呼び出しています。
foreach (var 体重データ in 体重データリスト) { Console.WriteLine($"{体重データ.StartTimeNanos.Value.FromGoogleTime().Date:yyyy-MM-dd} - {体重データ.Value[0].FpVal:F2}kg"); }
レスポンスのスキーマは以下のページを参照してください。 developers.google.com
構造が複雑でどこになんのデータがあるのか分かりづらいですが、体重データについて言えば基本的には次のプロパティを理解していればいいです。
Bucket(IList<AggregateBucket>)Dataset(IList<Dataset>)Point(IList<DataPoint>)StartTimeNanos(long?): 体重を記録開始した日時Value(IList<Value>)FpVal(double): これが体重の値
Google Fitness API を使って体重データを登録する
体重データを取得できたので、次は登録する方法について見ていきます。
実装
これを実行した結果はやりたいことに記載した通りです。CSV から読み込んだ体重データが無事に記録されています。
解説
OAuth 認証部分については省略します。CSV を読み込む部分も CsvHelper を使っているだけなので省略します。
最初にfitnessクライアント.Users.DataSources.Createの部分の説明からします。これはUsers.dataSources: createAPI を実行してデータソースを新規作成している部分です。
DataSource newDataset = fitnessクライアント.Users.DataSources.Create(body: new DataSource { Application = new Application { Name = "Upload from local" } , DataType = new DataType { Name = "com.google.weight" , Field = new List<DataTypeField> { new DataTypeField { Name = "weight" , Format = "floatPoint" } } } , Device = new Device { Manufacturer = "Original" , Model = "My PC" , Type = "unknown" , Uid = "<一意の値>" , Version = "1.0" } , Type = "raw" } , userId: "me") .Execute();
Google Fitness API では、体重などの身体情報を登録する際に特定のデータソースから登録したことを示す必要があります。これから登録しようとする環境=デバイスは存在しないため、新規に作成する必要があります。既存のデータソースを使用することはできません。今回の要件では登録は1回きりなので、適当な情報でデータソースの情報を埋めました。特にdeviceのmanufacturer, model, uid, versionプロパティは適当な値にしました。なお、このデータソースの作成は1回実行すれば良いので、2回目以降は実行されないようにしてください。
あとは、CSV から読み込んだ日時と体重データから登録したい Dataset を作ります。ちょっと面倒なのが日時がナノ秒であることです。体重データを取得する際はAggregateRequestでミリ秒だったのにここではナノ秒です。引っかかりやすそうなので注意してください。
Dataset[] 体重のDatasetリスト = 登録する体重情報.Select(x => new Dataset { DataSourceId = newDataset.DataStreamId , MinStartTimeNs = x.補正した時間GoogleAPI向け , MaxEndTimeNs = x.補正した時間GoogleAPI向け , Point = [ new DataPoint { DataTypeName = "com.google.weight" , StartTimeNanos = x.補正した時間GoogleAPI向け , EndTimeNanos = x.補正した時間GoogleAPI向け , Value = [new Value { FpVal = (double?)x.体重 }] // これが実際に登録する体重 } ] }).ToArray();
作成した Dataset を登録すれば完了です。
fitnessクライアント.Users
.DataSources
.Datasets
.Patch(body: 体重のDataset
, userId: "me"
, dataSourceId: newDataset.DataStreamId
, datasetId: $"{体重のDataset.MinStartTimeNs}-{体重のDataset.MaxEndTimeNs}")
.Execute();
Google Fitness API は実際に触ってみるとデータ構造と仕組みが複雑ですが、体重を取得・登録することはできます。 Google のことなので、Fit 自体ももしかしたらサービス終了する可能性もありますが、そうなった場合でもまとめて取得してしまえば移行も簡単ですね。
(C#/.NET) Fluent Assertions を使ってみる
先日、ChainingAssertion の GitHub ページを見たら2022年に public archive になっていました。
代替手段としてFluent Assertionsというものがリンクにあったので試しに使ってみたので、その内容をメモします。
参考
Fluent Assertionsはテストコードを自然言語のように記載することができるフレームワークです。
.NET のテスティングフレームワークのアサーションはAssert.Equals(expected, actula)のような形式が一般的で、地味に書き心地は良くないです。
同じようなアサーションでもFluent Assertionsであれば、actual.Should().Be(expected)のように記載することができます。
環境
- .NET 7
- Visual Studio 2022 Comunity
- Fluent Assertions 6.10.0
- xUnit.net 2.4.2
Fluent Assertions のバージョンはこのエントリ記載時点で最新のものを使用しています。 テスティングフレームワークは xUnit.net や NUnit、MSTestV2、NSpec、MSpec に対応しています。 今回は xUnit.net を使用しています。
インストール方法は以下を参考にしてください。
NuGet Gallery | FluentAssertions
基本的な使い方と特徴
基本的には検証したい値に対して.Should().~のようにアサーションを書いていきます。
アサーションは単体でも書けますし、And条件を追加することもできます。
string actual = "ABCDEFGHI"; // Should からアサーションが開始される。以降、条件を設定しつつアサーションを書いていく。 actual.Should().StartWith("AB") // 先頭に AB があること .And.EndWith("HI") // かつ、末尾が HI であること .And.Contain("EF") // かつ、EF が含まれること .And.HaveLength(9); // かつ、9文字であること。
Fluent Assertionsの特徴の一つがこれです。
Shouldから始まる事によって、アサーションそのものが値の確認とドキュメントとしての役割を果たしています。
テストコードを書くメリットの一つに「テストコードがドキュメントとしての役割を持つ」ことがありますが、よりわかりやいドキュメントとして成立させることができるようになります。
もう一つの特徴が「テスト失敗時になぜテストが失敗したのかわかりやすいメッセージを出力する」という点です。 Introduction の Getting startedにもありますが、通常のテストフレームワークよりも出力される情報量が多く、何が原因でテストが失敗しているのかわかりやすくなっています。
例えば、次のコードはテストに失敗します。
var numbers = new[] {1, 2, 3}; numbers.Should().HaveCount(4, "because we thought we put four items in the collection");
このとき、次のような失敗メッセージが出力されます。
Expected numbers to contain 4 item(s) because we thought we put four items in the collection, but found 3: {1, 2, 3}.
他にも、次のようなコードの失敗メッセージも、その原因がわかり易い内容で出力されます。
object theObject = null; theObject.Should().BeOneOf(1, "obj2", DateTime.Now);
Expected theObject to be one of {1, "obj2", <2023-04-14 00:39:55.9124061>}, but found
.
下記はAbout - Why?の引用ですが、明確な理由を説明していないテストの失敗メッセージは厄介で、失敗の原因を探るためにデバッガ地獄に陥る可能性があります。
ひとつのテストケースでひとつのことだけをテストするなどの対策もできますが、Fluent Assertionsを使えば失敗メッセージに含める情報が増えるためより効率的に対策することができます。
また、このメッセージはアサーションを実行する際にカスタマイズした情報も出力することができるようになっています。
Nothing is more annoying than a unit test that fails without clearly explaining why. More than often, you need to set a breakpoint and start up the debugger to be able to figure out what went wrong. Jeremy D. Miller once gave the advice to “keep out of the debugger hell” and I can only agree with that.
For instance, only test a single condition per test case. If you don’t, and the first condition fails, the test engine will not even try to test the other conditions. But if any of the others fail, you’ll be on your own to figure out which one. I often run into this problem when developers try to combine multiple related tests that test a member using different parameters into one test case. If you really need to do that, consider using a parameterized test that is being called by several clearly named test cases.
なお、アサーションに対して失敗メッセージがどのように出力されるかについては、以下のページに記載されています。 fluentassertions.com
使い方のパターン
実際に一通りドキュメントを読みながら、いくつか書いたテストコードの中で有用性の高そうなものや特徴のあるコードを紹介します。 なお、以下の公式ドキュメントを読めば大体の使い方はわかると思うので、読めばわかるようなコードは紹介しません。
文字列系
// 複数の期待値のうち、いずれかに一致すればテスト成功 "This is a String".Should().BeOneOf("That is a String", "This is a String"); // 期待値の文字列が2箇所以上含まれていればテスト成功 "This is a String. This is a String.is a".Should().Contain("is a", AtLeast.Twice()); // 次のコードは上記と同じことを検証している。 "This is a String. This is a String.is a".Should().Contain("is a", 2.TimesOrMore()); // ワイルドカードを使用した期待値が一致していればテスト成功 "firstname.lastname@example.com".Should().Match("*@*.com"); // 正規表現を使用して、期待値が一致していればテスト成功 "This is a String.".Should().MatchRegex("This\\s+is");
特に面白いのは.Contain()の部分です。
実際の値に対して、期待値がいくつ含まれているかを検証します。
シグニチャは以下のようになっています。
public AndConstraint<TAssertions> Contain(string expected, OccurrenceConstraint occurrenceConstraint, string because = "", params object[] becauseArgs)
このOccurrenceConstraintが回数を表しています。
以上、以下などの表現は次のようになっています。
| 指定方法 | 日本語訳 | サンプル |
|---|---|---|
Exactly |
ちょうど~ | Exactly.Once()で「一度だけ」 |
AtLeast |
少なくとも~ | AtLeast.Twice()で「少なくとも2回以上」 |
MoreThan |
~より多い | MoreThan.Thrice()で「3回より多い」 |
AtMost |
せいぜい~ | AtMost.Times(5)で「5回以下」 |
LessThan |
未満 | LessThan.Twice()で「2回未満」 |
すべての指定方法には1回Once(), 2回Twice(), 3回Thrice(), n回Times(n)のメソッドが用意されているので必要に応じて適宜指定すれば良いです。
また、OccurrenceConstraintには数値で回数を表現する拡張メソッドが用意されており、2.TimesOrMore()ような表現もできます。
(個人的にはこっちのほうが好み)
3.TimesExactly()= 3回 =Exactly.Thrice()と同じ3.TimesOrLess()= 3回以下 =AtMost.Thrice()と同じ3.TimesOrMore()= 3回以上 =AtLeast.Thrice()と同じ
実際の値が文字列であれば、.Match(), .NotMatch()でワイルドカードが使用できます。
.MatchRegrex(), .NotMatchRegrex()は正規表現を使用できます。
数値系
数値系で特記したいのは「丸め誤差に対するアサート方法」です。
Fluent Assertionsでは、丸め誤差に対するアサート方法が2種類あり、それぞれ次のようになります。
// 期待値に範囲を取るパターン。以下の例では実際の値が 0.3~0.31 であればテスト成功となる。 (0.1 + 0.2).Should().BeInRange(0.3, 0.31); // 期待値に近似値を使用するパターン。以下の例では実際の値が期待値(0.3)の誤差 ±0.01 に収まっていればテスト成功となる。 (0.1 + 0.2).Should().BeApproximately(expectedValue: 0.3, precision: 0.01);
日時系
日時は英語圏の書式で表現することができます。
var theDatetime = 1.March(2010).At(22, 15).AsLocal(); theDatetime.Should().Be(1.March(2010).At(22, 15));
正直、この書式に慣れていないと読みづらく感じるので、無理せず以下のようにしたほうが良いかな、と思います。
theDatetime.Should().Be(new DateTime(2010, 3, 1, 22, 15, 0));
また、特定部分の数値が一致しているかどうかを確認することもできます。
var theDatetime = new DateTime(2010, 3, 1, 22, 15, 0); // .Have~(expected) 系は、年月日時分秒が一致しているかどうかをテストできる。 // .HaveDay() であれば、日付部分のみ一致しているかどうかを見ている。 theDatetime.Should().HaveYear(2010); theDatetime.Should().HaveMonth(3); theDatetime.Should().HaveDay(1); theDatetime.Should().HaveHour(22); theDatetime.Should().HaveMinute(15); theDatetime.Should().HaveSecond(0);
コレクション系
コレクション系のアサートは以下のように「数+なにか」を確認する形式が多くなると思います。
IEnumerable<int> collection = new[] { 1, 2, 5, 8 }; collection.Should() .HaveCount(c => c > 3) // 要素数が 3 より大きい .And.OnlyHaveUniqueItems(); // コレクションの要素の値がすべて一意であることを検証する。
他にも、入れ子になった要素へアクセスするには.Witchを使用します。
var singleEquivalent = new[] { new { Size = 42 } }; singleEquivalent.Should().ContainSingle() .Which.Should().BeEquivalentTo(new { Size = 42 });
最初の.Should()でコレクションそのものに対するアサートを行い、.Witch.Should()で入れ子の要素に対するアサートを行います。
複雑なコレクションであっても、これでテストできます。
例外系
スローされた例外がArgumentNullExceptionの場合、スローされる原因となった引数名を検証することもできます。
var action = () => new TestTarget().ThrowArgumentNullException(null, "Smith"); action.Should().Throw<ArgumentNullException>().WithParameterName("value");
他にも、一定期間中に例外がスローされて、時間が経過すると例外がスローされなくなるような動作も検証することができます。 何らかの異常時から復旧するような振る舞いをテストするときとかに使えそうですね。 (ドキュメントでは「特定の時間経過すると復旧するネットワークをテストするときなど」と記載している。)
// こんなクラスをテストするものとする。 public class TestTarget { private readonly Stopwatch _stopwatch = new(); public bool Retry() { if (!_stopwatch.IsRunning) _stopwatch.Restart(); if (_stopwatch.Elapsed < 2.Seconds()) throw new InvalidOperationException("まだ2秒経過してないよ。"); _stopwatch.Stop(); return true; } }
var testTarget = new TestTarget(); var action = () => testTarget.Retry(); // 第一引数は「例外がスローされなくなる時間」、第二引数は例外がスローされてから再度 action を実行するまでの間隔。 // つまり、以下は例外がスローされてから次の実行まで1秒間待機して、3秒経過したときには例外がスローされなければテスト成功となる。 action.Should().NotThrowAfter(3.Seconds(), 1.Seconds());
上記の例では、AAA パターンの Arrange に該当するコードがちょっと冗長なので、以下のように書くこともできます。
// FluentActions.Invoke() は同期アクション // FluentActions.Awaiting() は非同期アクション // FluentActions.Enumerating() は列挙シーケンスを実行する際に使用することができる。 FluentActions.Invoking(() => new TestTarget().ThrowArgumentNullException(null, string.Empty)).Should().ThrowExactly<ArgumentNullException>();
実行時間を計測する系
ある処理の実行時間を計測することもできます。
Worker worker = new Worker(); // あるメソッドの実行時間を計測し、その時間が期待値以下かどうかを判定することができる。 // 次のように、<テスト対象クラス>.ExecutionTimeOf() で計測対象のメソッドを呼び出し // .Should().BeLessThanOrEqualTo() で時間を指定することができる。 worker.ExecutionTimeOf(x => x.Work()).Should().BeLessThanOrEqualTo(100.Milliseconds());
時間の判定方法には次のようなものがあります。
.BeGreaterThanOrEqualTo(5.Seconds()): 5秒以上.BeLessThanOrEqualTo(5.Seconds()): 5秒以下.BeGreaterThan(5.Seconds()): 5秒より長い.BeLessThan(5.Seconds()): 5秒未満.BeCloseTo(5.Seconds(), 200.Milliseconds()): 5秒から±200ミリ秒の誤差の範囲
Web API 系
HttpClientを使って Web API を呼び出すようなアサートも用意されています。
using var client = new HttpClient(); var response = await client.GetAsync("https://xxx.com/api/~~"); // .HaveStatusCode() で具体的なステータスコードを判定する。 response.Should().HaveStatusCode(HttpStatusCode.OK); // .BeSuccessful() は 2xx 系かどうかを判定する。 response.Should().BeSuccessful(); // HttpResponseMessage では、以下のような検証も可能になっている。 // 例: ヘッダーに"Content-Type"が含まれていて、一つの値を持っていて"application/json; charset=utf-8"であること。 response.Content.Headers .Should().ContainKey("Content-Type") .WhoseValue .Should().ContainSingle(x => x == "application/json; charset=utf-8");
API テストでヘッダー情報の検証をする場合は重宝しそうです。
また、レスポンスのペイロードを検証する際はFluentAssertions.Jsonをインストール必要があります。
以下参照
github.com
Newtonsoft.Json.Linq.JTokenにパースした json に対してアサートを定義することでテストできます。
// これを使うことで、JToken に変換した json オブジェクトの検証が可能になる。 // 次のコードでは、応答結果の json に"longitude"という要素が含まれているかどうか、かつその値に"135.5"があるかどうかを検証している。 JToken.Parse(await response.Content.ReadAsStringAsync()).Should().HaveElement("longitude") .Which .Should().HaveValue("135.5");
厳密な比較や特定の要素の値をキャストしてアサートすることもできるので、詳細はドキュメントを参照してください。
Analyzer
アサートの書き方によってはテスト失敗時のメッセージに出力される情報が制限され、原因調査に必要な情報が得られない場合があります。
いくら気を使っていても人間なので推奨されない記法になってしますが、FluentAssertions Analyzersを使えば Visual Studio のクイックアクションでより自然言語のように、かつ必要な失敗メッセージを出力できるようなコードを提案してくれます。
具体的には以下のリンクを参照してほしいですが、Fluent Assertionsを使う場合はこちらもインストール推奨です。
実装したコード
参考までに、Fluent Assertionsを使って実装したコードのリンクを置いておきます。
https://github.com/Iyemon-018/Learning.CSharp.OSS/tree/main/src/Learn.FluentAssertions
.NET でコードカバレッジを収集&レポートする
.NET6 を使ったアプリの開発中にコードカバレッジの収集とレポートを出力しようとしたのですが、地味に情報がまとまっていなかったので残しておこうと思います。
なお、コードカバレッジにはcoverlet.collector、レポート出力にはReportGeneratorを使用します。
coverlet.collectorはxUnit.NETが規定で統合しているため、選択肢として挙がりやすいと思います。
開発環境
- Visual Studio 2022
- .NET 6.0.300
- coverlet.collector 3.1.2
- ReportGenerator 5.1.9
使用するソリューション
今回使用するソリューションはシンプルにコンソールアプリとしています。
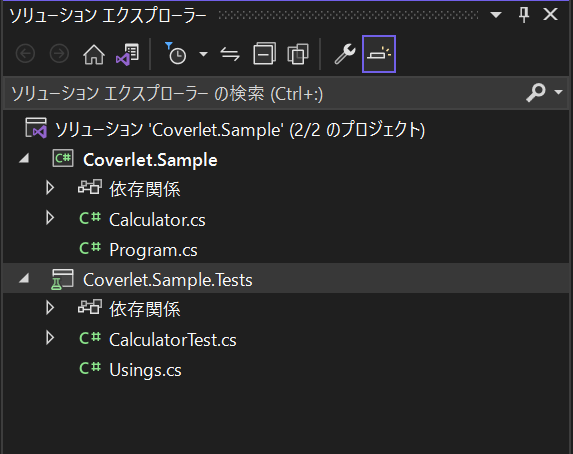
Coverlet.Sampleプロジェクトに実装コードが含まれていて、Coverlet.Sample.Testsにテストコードを実装するような構成です。
テストするのは次のようなCalculatorクラスとします。
public class Calculator { public int Add(int x, int y) => x + y; public int Subtract(int x, int y) => x - y; }
ReportGenerator をインストールする
基本的に以下の Microsoft Docs を読めばいいんですが、地味に間違っているのがReportGeneratorのインストールコマンドです。
ドキュメントには次のコマンドが記載されていますが、私のローカル環境で実行したところ失敗しました。
dotnet tool install -g dotnet-reportgenerator-globaltool
こんなメッセージが出力されます。 PS C:\Users\user> dotnet tool install -g dotnet-reportgenerator-globaltool
C:\Users\user\AppData\Local\Temp\xwqllpoi.5zb\restore.csproj : error NU1301: ソース https://pkgs.dev.azure.com/iyemon018/ _packaging/All-Packages/nuget/v3/index.json のサービス インデックスを読み込めません。 ツール パッケージを復元できませんでした。 ツール 'dotnet-reportgenerator-globaltool' をインストールできませんでした。この失敗は次の原因で生じた可能性があります。 * プレビュー リリースをインストールしようとしており、--version オプションを使用してバージョンを指定しなかった。 * この名前のパッケージが見つかったが、.NET ツールではなかった。 * 恐らくインターネットの接続の問題で、必須の NuGet フィードにアクセスできない。 * ツールの名前の誤入力。 パッケージの名前付けの強制を含む他の理由については、https://aka.ms/failure-installing-tool にアクセスしてください
実際にはこちらのページに記載されているコマンドを実行します。
次のコマンドであれば成功すると思います。
dotnet tool install --global dotnet-reportgenerator-globaltool --version 5.1.9
テストを実行する
xUnit.NET + coverlet.collectでテストを実行するだけであれば次のコマンドを実行するだけで問題ありません。
dotnet test --collect:"XPlat Code Coverage"
ただし、出力される XML ファイルをレポートツールに食わせて出力する場合、フォーマットを指定する必要があります。
フォーマットのオプションはcoverlet.collectionのプロジェクトに記載されています。
フォーマットのデフォルトはcoberturaになっているので、今回のケースでは使用しなくてもいいのですが覚えておくと応用が効きます。
coberturaのフォーマットで実行する場合は次のコマンドを実行します。
dotnet test --collect:"XPlat Code Coverage" -- DataCollectionRunSettings.DataCollectors.DataCollector.Configuration.Format=cobertura
データ収集構成を設定ファイルで定義する
コマンドでフォーマットを指定することも可能なのですが、coverlet.collectではそれ以外にもデータ収集構成を設定することが出来ます。
このデータ収集構成は XML ファイルとして定義でき、実行時に指定することが出来ます。
チームで開発する場合は、このデータ収集構成の設定ファイルを Git に保存しておけば、どの環境でも同一のレポートを出力することが出来ますし、CI を使って出力する際にも使用できます。
データ収集構成は次のような構成になっています。具体的なそれぞれの項目の意味は、上記のcoverlet.collectionプロジェクトページを参照してください。
<?xml version="1.0" encoding="utf-8" ?>
<RunSettings>
<DataCollectionRunSettings>
<DataCollectors>
<DataCollector friendlyName="XPlat code coverage">
<Configuration>
<Format>json,cobertura,lcov,teamcity,opencover</Format>
<Exclude>[coverlet.*.tests?]*,[*]Coverlet.Core*</Exclude> <!-- [Assembly-Filter]Type-Filter -->
<Include>[coverlet.*]*,[*]Coverlet.Core*</Include> <!-- [Assembly-Filter]Type-Filter -->
<ExcludeByAttribute>Obsolete,GeneratedCodeAttribute,CompilerGeneratedAttribute</ExcludeByAttribute>
<ExcludeByFile>**/dir1/class1.cs,**/dir2/*.cs,**/dir3/**/*.cs,</ExcludeByFile> <!-- Globbing filter -->
<IncludeDirectory>../dir1/,../dir2/,</IncludeDirectory>
<SingleHit>false</SingleHit>
<UseSourceLink>true</UseSourceLink>
<IncludeTestAssembly>true</IncludeTestAssembly>
<SkipAutoProps>true</SkipAutoProps>
<DeterministicReport>false</DeterministicReport>
</Configuration>
</DataCollector>
</DataCollectors>
</DataCollectionRunSettings>
</RunSettings>
-- DataCollectionRunSettings.DataCollectors.DataCollector.Configuration.Format=coberturaと同じ構成にする場合は次のようにすればOKです。
<?xml version="1.0" encoding="utf-8" ?>
<RunSettings>
<DataCollectionRunSettings>
<DataCollectors>
<DataCollector friendlyName="XPlat code coverage">
<Configuration>
<Format>cobertura</Format>
</Configuration>
</DataCollector>
</DataCollectors>
</DataCollectionRunSettings>
</RunSettings>
あとは次のコマンドを実行すれば設定ファイルを使用してテストの実行とコードカバレッジの収集を実行してくれます。
dotnet test --collect:"XPlat Code Coverage" --settings coverlet.collect.runsettings
レポートを出力する
テストとコードカバレッジ収集を実行すると、テストプロジェクトのフォルダ配下にTestResultsフォルダが作成され、その配下にcoverage.cobertura.xmlファイルが生成されます。
このファイルを使用して以下のコマンドを実行するとレポートが出力されます。
reportgenerator -reports:"Coverlet.Sample.Tests\TestResults\{guid}\coverage.cobertura.xml" -targetdir:"coveragereport" -reporttypes:Html
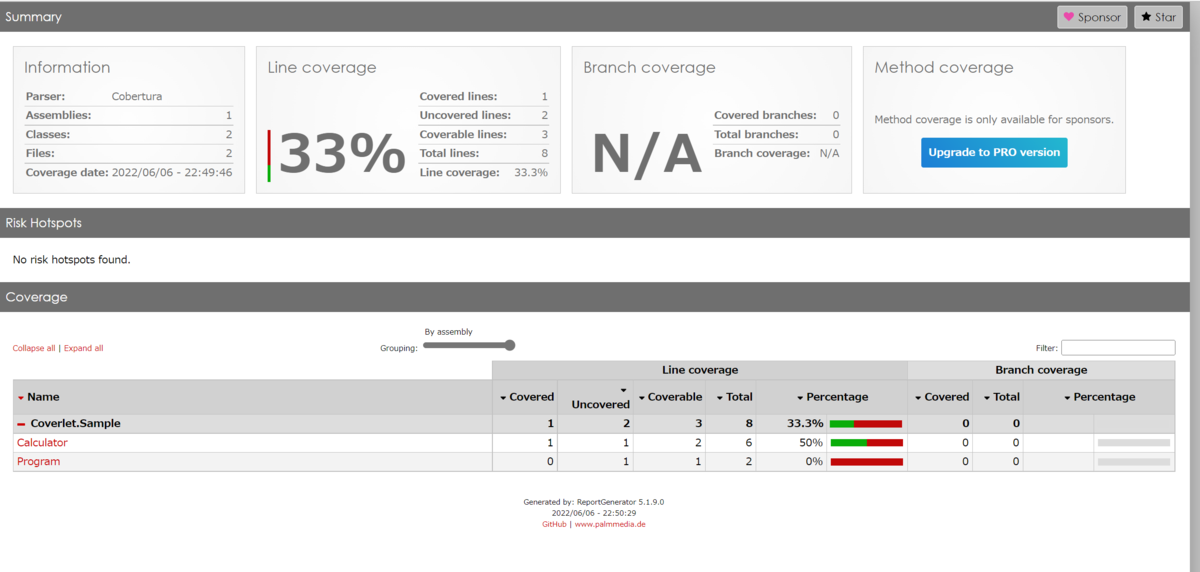
レポートはこんな感じで出力されます。

スクリプトで実行できるようにする
コマンドラインで毎回実行するのは時間の無駄なのでテスト実行+コードカバレッジ収集+レポート出力をPowerShellで実行できるようにします。
今回のソリューションでは次のようにしました。
$runSettings = ".\runsettings.xml"
$resultDirectory = ".\.TestResults"
$reportsDirectory = ".\.TestReports"
if (Test-Path $resultDirectory) { Remove-Item $resultDirectory -Recurse }
if (Test-Path $reportsDirectory) { Remove-Item $reportsDirectory -Recurse }
dotnet test .\Coverlet.Sample.Tests\Coverlet.Sample.Tests.csproj --collect:"XPlat Code Coverage" --results-directory $resultDirectory --settings $runSettings
$xmlFileName = (Get-ChildItem $resultDirectory -Filter *.xml -Recurse -File)[0].FullName
reportgenerator -reports:$xmlFileName -targetdir:$reportsDirectory -reporttypes:Html
設定ファイルはrunsettings.xmlに保存しておき、コードカバレッジは.TestResultsフォルダに出力します。
coverlet.collectはカバレッジ結果の出力フォルダを GUID で生成するため、固定のフォルダ名にすることが出来ません。
仕方ないのでGet-ChildItemでフルパスを取得するようにしています。
コードカバレッジの収集とレポート出力はあまりキャッチアップしないせいか気がつくと過去のプロジェクトでは使用できなくなっていたりします。 .NET の場合は LTS が GA されたタイミングで定期的に見直していくのが良さそうですね。
(Azure Pipelines) ビルドパイプラインの使用するリソースの値を表示する
Azure Pipelines ではパイプライン外でresourcesとして定義しているリソースの値があります。
例えば、repositoriesを使用すると別サービスのリポジトリをチェックアウトすることも可能になっており、他にもpipelinesやcontainersなどを利用することができます。
<resourcesのスキーマ>
resources: pipelines: [ pipeline ] builds: [ build ] repositories: [ repository ] containers: [ container ] packages: [ package ] webhooks: [ webhook ]
スキーマは以下のリンクから抜粋しています。
これらの値を定義することは簡単なのですが、どのようなプロパティがあり、どのような値が設定されているのかはドキュメントを読んでもイマイチピンときません。 今回は偶然?このリソースの値を表示する方法を見つけたので備忘録として残しておきます。
リソースって何?って方は以下のリンクを読んでください。
リソースの値を参照するyaml
結論から先に。 リソースの値を参照するには yaml で以下のように各リソースを JSON へ変換します。
variables: pipelineVar: $[ convertToJson(Pipeline) ] # resources.pipeline properties resourcesVar: $[ convertToJson(resources) ] # resources properties variablesData: $[ convertToJson(variables) ] # variables properties
定義する場所は yaml のルートでもいいですし、stageやjob配下でもいいです。
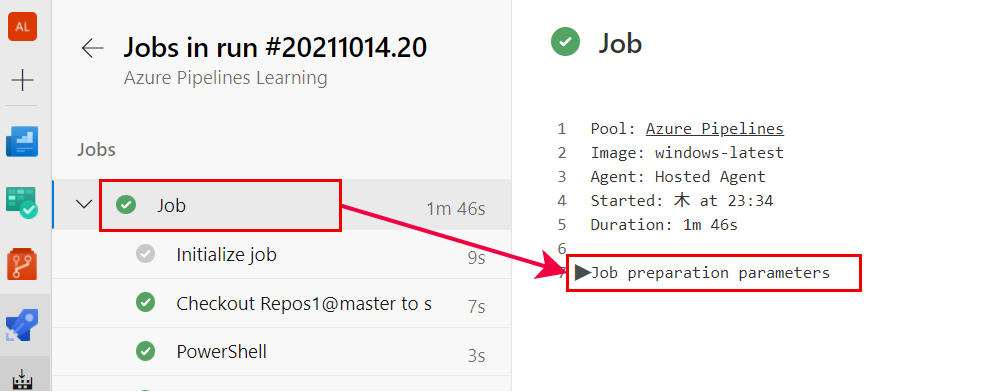
これを定義したビルドを実行すると、以下のようにログ画面からジョブ名→Job preparation parametersを選択するとリソースの値が JSON 形式で表示されます。
実際には以下のような値が表示されます。
今回はresources - repositoriesで別リポジトリを参照している yaml を利用しました。
なので、他のリソースの値は表示されていません。pipelinesやcontainersを設定している場合は同様にログに出力されます。
Job preparation parameters
Variables:
variablesData:
Parsing expression: <convertToJson(variables)>
Evaluating: convertToJson(variables)
Result: '{
"resources.triggeringCategory": "",
"resources.triggeringAlias": "",
"variablesData": "$[ convertToJson(variables) ]",
"pipelineVar": "$[ convertToJson(Pipeline) ]",
"resourcesVar": "$[ convertToJson(resources) ]",
"system": "build",
"system.hosttype": "build",
"system.servertype": "Hosted",
"system.culture": "en-US",
"system.collectionId": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"system.collectionUri": "https://dev.azure.com/<Organization>/",
"system.teamFoundationCollectionUri": "https://dev.azure.com/<Organization>/",
"system.taskDefinitionsUri": "https://dev.azure.com/<Organization>/",
"system.pipelineStartTime": "2021-10-14 23:33:56+09:00",
"system.teamProject": "Azure Pipelines Learning",
"system.teamProjectId": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"system.definitionId": "21",
"build.definitionName": "Azure Pipelines Learning",
"build.definitionVersion": "1",
"build.queuedBy": "<User Name>",
"build.queuedById": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"build.requestedFor": "<User Name>",
"build.requestedForId": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"build.requestedForEmail": "<User unique name>",
"build.sourceVersion": "xxxxxxxxxxxxxxxxxxxxxxxxxxx",
"build.sourceBranch": "refs/heads/master",
"build.sourceBranchName": "master",
"build.reason": "Manual",
"system.pullRequest.isFork": "False",
"system.jobParallelismTag": "Private",
"system.enableAccessToken": "SecretVariable",
"MSDEPLOY_HTTP_USER_AGENT": "VSTS_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"AZURE_HTTP_USER_AGENT": "VSTS_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"build.buildId": "1214",
"build.buildUri": "vstfs:///Build/Build/1214",
"build.buildNumber": "20211014.20",
"build.containerId": "6470472",
"system.isScheduled": "False",
"system.definitionName": "Azure Pipelines Learning",
"system.planId": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"system.timelineId": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"system.stageDisplayName": "__default",
"system.stageId": "96ac2280-8cb4-5df5-99de-dd2da759617d",
"system.stageName": "__default",
"system.stageAttempt": "1",
"system.phaseDisplayName": "",
"system.phaseId": "d768f2aa-2c4b-5810-be30-11cbf757b796",
"system.phaseName": "Job1",
"system.phaseAttempt": "1"
}'
pipelineVar:
Parsing expression: <convertToJson(Pipeline)>
Evaluating: convertToJson(Pipeline)
Result: '{
"startTime": "2021-10-14 23:33:56+09:00"
}'
resourcesVar:
Parsing expression: <convertToJson(resources)>
Evaluating: convertToJson(resources)
Result: '{
"repositories": {
"self": {
"id": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"name": "Azure Pipelines Learning",
"ref": "refs/heads/master",
"type": "Git",
"url": "https://dev.azure.com/<Organization>/Azure Pipelines Learning/_git/Azure Pipelines Learning"
},
"REPOS1": {
"id": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"name": "Repos1",
"ref": "refs/heads/master",
"type": "git",
"url": "https://dev.azure.com/<Organization>/Azure Pipelines Learning/_git/Repos1"
}
},
"containers": {}
}'
ContinueOnError: False
TimeoutInMinutes: 60
CancelTimeoutInMinutes: 5
Expand:
MaxConcurrency: 0
variables の値も表示できる
地味にありがたいのがsystemやbuildの値が表示されることですね。
variablesも JSON で出力できるのでコンパイル時点で出力可能な変数については確認することができます。
ドキュメントに記載されていないプロパティも確認できる
例えば、resourcesのプロパティって何が定義されているのかドキュメントに記載されていません。
yaml を書く際のプロパティはスキーマのドキュメントにはあるのですが、値を参照するときの情報は皆無で必要になった場合は大変困ります。
このあたりにちょろっと.refsとかは書かれていますが、その程度です。
この手法を使えばrefやtype, urlなどが取得可能なことがわかります。
resourcesVar:
Parsing expression: <convertToJson(resources)>
Evaluating: convertToJson(resources)
Result: '{
"repositories": {
"self": {
"id": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"name": "Azure Pipelines Learning",
"ref": "refs/heads/master",
"type": "Git",
"url": "https://dev.azure.com/<Organization>/Azure Pipelines Learning/_git/Azure Pipelines Learning"
},
"REPOS1": {
"id": "xxxxxxx-xxxxxxx-xxxxx-xxxx-xxxx",
"name": "Repos1",
"ref": "refs/heads/master",
"type": "git",
"url": "https://dev.azure.com/<Organization>/Azure Pipelines Learning/_git/Repos1"
}
},
取得できない値
AgentEnvironmentBuild,Systemの一部の値
定義済みの変数で上記の値は存在することはわかっていますが、この手法で参照することはできません。
variablesの各変数がどのような値を参照しているかなどは yaml の動作検証やバグ発生時に役立つかもしれません。
あとはresources - repositoriesで別リポジトリを参照している場合に、リポジトリの情報を通知したいシーンなどで、どのプロパティがどのような値か確認する場合にも利用できます(私の場合はこちらの調査で偶然この方法を見つけました)。